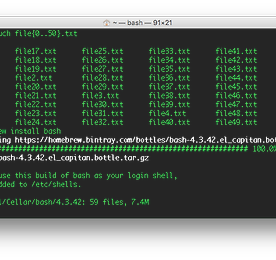
Programming 썸네일형 리스트형 [BASH] 기본 BASH 업그레이드 및 활용하기 맥에 기본으로 깔려 있는 bash 를 업그레이드 해 보려고 한다. 우선 현재 깔려 있는 bash 버전을 확인해 보았다. 3.2.57 버전이 기본으로 맥에 깔려 있다.그럼 bash 를 왜 업그레이드 해야 할까?대부분의 이용자에게 별 문제없는 기능중 하나일 것이다. 그렇지만 터미널을 많이 사용하는 이들에겐 최신 bash 기능이 없을때 아쉬울 수가 있다. 그 중 bracket expansion 기능을 알아보자. {} 문자를 이용해서 범위를 지정할 수 있는 기능이다. {시작..끝} 이렇게 범위를 지정해서 사용하면 알아서 채워준다. 이와 같은식으로 사용할 수 있다. 어디에 활용할 수 있을까? 파일 이름에 숫자가 이어지는 파일을 한 50개 만들고 싶다고 한다면 아래와 같이 하면 된다. 맥에 기본으로 깔려 있는 ba.. 더보기 [PYTHON 3] Tutorials 3. Strings string 은 컴퓨터 프로그래밍에서 일종의 텍스트라고 생각하시면 됩니다. 가령, 이름, 문장등과 같은것을 일컬어 string이라고 할 수 있겠죠. 파이썬에서는 string 을 사용하기 위해서는 single quote(' ') 혹은 double quote(" ") 을 사용합니다. 위 문장들에서 " " , ' ' 안에 있는 것을 string으로 인식합니다. 위 문장에서 'I don't think she is 20' 이 부분은 오류가 있습니다. ' ' 은 시작과 끝을 알려주어야 하는데 don't 에도 single quote가 있어서 이 부분을 문장의 끝으로 인식을 해 버린 것입니다. 이럴경우 아래 그림과 같이 double quote을 사용하여 문제 해결을 합니다. double quote 을 사용하여 문장 전.. 더보기 [PYTHON 3] Tutorials 2. Numbers 안녕하세요. 이번 시간에는 파이썬에서 숫자는 어떻게 다루는지 간략히 보도록 하겠습니다. 말그대로 간략하기에, 이번에는 파이썬 인터프리터를 활용해서 진행하겠습니다. 맥에 있는 터미널(Terminal) 을 띄웁니다. 파이썬 3 버전이 깔려 있다면 아래와 같이 "python3" 이라고 넣으면 됩니다. 만약 파이썬이 깔려 있지 않다면 [MAC TIP] Mac에 Homebrew 설치하기를 참조하여 homebrew를 설치 하신 이후에 brew install python3 실행하시면 설치가 될 것입니다. 터미널에서 python3 를 넣습니다. 파이썬 인터프리터가 실행 된 모습입니다. 기본인 사칙 연산을 해보도록 하겠습니다. 정수(Integer)인 3 + 4 를 실행한 모습입니다. 결과는 7 이겠죠.. 3 * 20 의.. 더보기 [PYTHON 3] Tutorials 1. Python Installation 안녕하세요. Jason 입니다. 앞으로 시간이 있을 때 파이썬 튜토리얼을 조금씩 만들어서 올려보려고 합니다. 프로그램 초심자들도 쉽게 익힐 수 있는 언어 중 하나인 파이썬을 소개하고 조금이나마 컴퓨터를 활용한 생산성 향상에 도움이 되었으면 하여 시작하게 됨을 알려드립니다. 저의 컴퓨터 환경은 맥을 기반으로 하고 있어서 맥 위주로 설명이 이루어 지겠으나, 윈도우나 리눅스 등 여타 다른 OS 에서도 크게 다르지 않습니다. 읽어 보시고 궁금한 점이 있으시면 아는 한도내에서 설명을 드리겠습니다. 그럼 시작을 해 볼까요? 우선 파이썬을 시작하기에 앞서 프로그램을 설치해야겠죠? 아래 보이는 python.org 에 들어가셔서 다운받아 설치하셔도 됩니다. 주소는 : https://www.python.org 입니다. 그.. 더보기 [PYTHON] Python을 이용한 웹사이트 스캐너 만들기 - 7. 완결편 이번 시간에는 그동안 만들어 둔 함수들을 가지고 종합적으로 다루어 보도록 하겠습니다. 1편 소개편에서 말씀드린것 처럼 이것을 가지고 자신에게 보다 더 유용한 방향으로 수정, 편집해서 사용하시면 도움이 되리라 봅니다. 그럼 시작해보겠습니다. 1. 가장 처음 만들어 둔 main.py로 이동을 합니다. 여기에서 위와 같이 앞에서 만든 함수들을 불러옵니다. 2. ROOT_DIR 를 'sites' 라는 이름으로 지정을 해주었습니다. 향후 이 'sites' 폴더 밑에 각 사이트의 정보가 쌓이게 될 것입니다. 3. ROOT_DIR을 만들어 줄 것입니다. 아직 create_dir 함수를 정의하지 않았는데, 이는 아래에서 다룰 예정입니다. 4. 이제까지 만든 함수들을 종합적으로 다룰 함수 'gather_info'를 정의.. 더보기 [PYTHON] Python을 이용한 웹사이트 스캐너 만들기 - 6. whois 이제 거의 짧은 여정이 끝이 나갑니다. 이번 시간에는 'whois' 를 파이썬으로 구현해 보겠습니다. 1. whois.py 파일을 만들어 줍니다. 2. 여느때와 마찬가지로 os 를 임포트 해 줍니다. 3. whois 를 얻기 위한 함수를 정의해 줍니다. 4. 명령어에 "whois " + url 이 들어갈수 있도록 변수를 지정합니다. 한가지 주의할 점은 whois 뒤에 공백(스페이스)을 넣어 주어야 합니다. 아니면 whois 와 조사할 타겟 사이트가 붙어버려 명령이 수행 안되니까요. 5. 그렇게 지정한 명령어를 프로세스로 지정. 7. 지정된 프로세서를 result 에 넘겨주면서 string 로 컨버팅해줍니다. 8. 이렇게 컨버팅 된 result 를 리턴하면 끝입니다. 9. 이제 확인! 아래와 같이 프린트를.. 더보기 [PYTHON] Python을 이용한 웹사이트 스캐너 만들기 - 5. robots.txt 이번 시간에는 robots.txt 에 대해 알아보려고 합니다. robots.txt 파일이 어떤 역할을 하냐면, 웹을 만들때 구글이나, 야후, 네이버, 다음과 같은 검색엔진에서 크롤링(사이트를 프로그램으로 자동 저장하는것)을 하는데 이때 민감한 페이지나 관리자 페이지 같은것은 크롤링 하지 못하게 텍스트 파일 형태로 작성해 둔 것입니다. 보다 자세한 사항은 Robots.txt 링크를 참조하시면 이해하실 수 있을것 입니다. 자 그럼 시작해 보겠습니다. 1. 우선 robots_txt.py 파일을 만들어 주고 import urllib.request 를 작성해 줍니다. urllib 와 request 는 웹과 관련된 파이썬 모듈입니다. 2. io 또한 임포트 해줍니다. 3. get_robots_txt 함수를 정의하고.. 더보기 [PYTHON] Python을 이용한 웹사이트 스캐너 만들기 - 4. Nmap Port Scan 이제 타겟 서버의 아이피 주소까지 얻었습니다. 이제부터는 nmap을 사용하여 타겟 서버의 포트 개방 여부를 확인하고, 어떤 프로세서가 러닝되고 있는지 확인하려고 합니다. 그러기 위해서는 'NMAP' 이 설치가 되어 있어야 합니다. 맥을 사용하시는 분들이라면 homebrew 를 설치하신 이후에 brew install nmap 을 하시면 설치하실수 있습니다. 물론 리눅스를 설치하고 계신분은 바로 인스톨 하시면 됩니다. NMAP 으로 확인하려고 하는 결과를 먼저보여 드리면 아래 그림과 같습니다. 앞에서 얻은 tistory.com 의 아이피 주소인 180.70.93.117 을 넣어보니 http 프로토콜의 포트번호인 80번과, https의 포트번호인 443만 개방되어 있는것을 확인하실 수 있습니다. 자 그럼 본격.. 더보기 [PYTHON] Python을 이용한 웹사이트 스캐너 만들기 - 3. IP Address 2편에서 tld(Top Level Domain)을 얻었습니다. 이제는 스캐닝을 할 웹사이트의 ip address 를 얻을 필요가 있습니다. 위와 같이 티스토리의 아이피는 180.70.93.117 이네요. 그렇지만 우리가 원하는 정보는 이 IPv4에 해당하는 숫자만 필요합니다. 즉, 프로그램적으로 앞부분의 'history.com has address ' 이 부분을 날려버리면 됩니다. 혹은 뒷 부부만 선택적으로 받아들이게 하면 됩니다. 1. 아이피를 얻기위해 위와같이 파일을 만들어 줍니다. 2. 위의 터미널에서 보여진대로 특정 정보만 취사선택 하기위해 이번에도 os 를 임포트 해줍니다. 3. 아이피 정보를 얻기 위한 함수를 선언. 4. 위의 터미널에서의 명령을 파이썬으로 프로그램적으로 구동 시키기 위한 방법.. 더보기 [PYTHON] Python을 이용한 웹사이트 스캐너 만들기 - 2 최상위 레벨 도메인 이름 Top level of Domain 은 가령. 티스토리 같은경우 http://www.tistory.com 이렇게 URL 이 있다고 하면 여기에서는 history.com 이 부분이 top level of domain 에 해당한다. 즉, 프로토콜(http), WWW 은 제외단되는 말이다. 터미널창에서 보다 자세히 확인해 보자. 위와 같이 터미널에서 프로토콜, www을 함께 넣으면 whois 명령어가 인식을 못하니 제대로 넣으라고한다. 그럼 아래처럼 하면 어떻까? 티스토리의 정보가 쫘~~악 뜬다. 음..과금 담당자의 연락처라든지.... ㅎㅎ 자 그럼 이러한 정보를 smooth하게 한방(?)에 해결하기 위해 시작해보자. 1. domain_name.py 파일을 만들어 주고 from tld import get_tl.. 더보기 [PYTHON] Python을 이용한 웹사이트 스캐너 만들기 - 1. 소개 파이썬을 이용해 간략한 웹사이트 스캐너를 만드는 과정을 소개하려 한다. 프로그래밍을 공부하는 분들에게 조금이나마 도움이 되었으면 하는 바람으로 이 글을 작성합니다. 금일 기준(2015년 10월 30일) 정말 개략적인 소개입니다. 여기에 아이디어를 덧붙여 본인에게 맞는 프로그램을 작성해 보시면 유용하리라 생각합니다. 자 그럼 시작해 보겠습니다. 우선. 이글은 파이썬이 어떤것이며, 본인의 컴퓨터에 깔려 있다는 전제하에 진행됩니다. 추후 기초적인 것부터 소개하는 글을 따로 올리겠지만, 현 시점에서는 건너띄고 진행하겠습니다. 또한, 베이스 OS 는 리눅스이면 금상첨화일 것입니다. 저는 맥에서 'Homebrew'를 이용해 리눅스 명령어를 설치해 사용하고 있습니다. 그리고 아래 IDE 툴은 Pycharm 이라고 불.. 더보기 [Ruby] Node.js를 이용하여 웹 사이트 데이터 가져오기(web scraping, Phantomjs) 서론우리는 흔히 데이터를 데이터베이스에서 가져온다고 생각한다. 실제 웹사이트를 구축할 때 웹 페이지를 생성하기 위해서 웹 프로그램이 데이터베이스에서 데이터를 조회해서 웹 페이지를 만드는데 요즘은 API 서비스들이 많기 때문에 데이터를 가져오는 것이 데이터베이스에만 국한되지 않고 API를 통해서 가져오기도 한다. 하지만 API를 지원하지 않는 서비스에서 데이터를 가져오는 방법은 없을까? 고민하게 되는 경우도 있다. 예를 들어서, 석사때 학교 기숙사에 지내면서 기숙사 게시판의 공지를 매번 사이트에 들어가서 확인하는 것이 불편하고 또 중요한 공지사항이 있음에도 불구하고 시간이 없어서 웹 사이트를 방문하지 않아서 공지를 놓치는 경우가 많았었다. 그래서 ruby로 웹 사이트의 HTML 코드를 가져와서 분석해서 새.. 더보기 [Bash] Photos, Files auto sorting script on Windows,Linux,Mac by dates setlocal enabledelayedexpansion set /p input=Enter the target directory:%=% set RawData=!input!\*.* set target_folder=x:\ for %%a in ("%RawData%") do ( echo Processing %%~nxa ... set File=%%~fa for /f "tokens=1* delims=," %%a in ('wmic datafile where "name='!File:\$ echo %%~nxa: !LastModified! set cYear=!LastModified:~0,4! set cMonth=!LastModified:~4,2! set cDay=!LastModified:~6,2! set TimeStamp.. 더보기 [Ruby] Install nokogiri on Ubuntu. Ruby를 사용하여 HTML을 파싱하기 위해서 nokogiri를 사용려고 Ubuntu에 nokogiri를 설치하면 libxml2를 찾지 못한다는 에러를 만나게 된다. $ sudo gem install nokogiri ERROR: Error installing nokogiri:ERROR: Failed to build gem native extension. /usr/bin/ruby1.8 extconf.rbchecking for libxml/parser.h... no-----libxml2 is missing. please visit http://nokogiri.org/tutorials/installing_nokogiri.html for help with installing dependencies.-----**.. 더보기 이전 1 2 3 4 5 다음